
株式会社オンリーストーリーが運営する決裁者マッチングアプリ「ONLYSTORY」の「決裁者インタビュー」に弊社執行役員 日向野 信吾のインタビュー記事が掲載されました。
■オンリーストーリー:インタビュー記事はこちら
https://onlystory.co.jp/stories/it/30th/3081
株式会社オンリーストーリーが運営する決裁者マッチングアプリ「ONLYSTORY」の「決裁者インタビュー」に弊社執行役員 日向野 信吾のインタビュー記事が掲載されました。
■オンリーストーリー:インタビュー記事はこちら
https://onlystory.co.jp/stories/it/30th/3081

“企業文化を何より大切にした組織を創り、お客さまを支援したい”という想いから誕生した「SENZOKU LAB.」にて、導入いただいている企業さまの事例記事を公開いたしました。
今回の導入事例では、株式会社ユーザベース様をご紹介しております。
リソースの不安定さに課題を抱えていた、イレギュラー要素を抱えたオペレーションが複数存在していた、とおっしゃるユーザベース様に、導入後の良かった点や決め手、“人が辞めてしまう”悩みから解放されたと言っていただいた導入後の変化などインタビューにお答えいただきました。
ぜひご覧ください。

「SENZOKU LAB.」は単なるリソース提供ではなく、お客さまの目指すビジョン、大切にされている価値観(フィロソフィ)を理解したカルチャーフィットする組織をお客さまと一緒に創りあげ、成長させていきます。
「SENZOKU LAB.」サービス紹介ページはこちら
オンライン相談予約を随時受付中です。
こんにちは。編集部の福田です。
突然ですが皆さん、1日に何回くらいネット検索しますか?
私は20~30回くらいでしょうか。
よく「ググる」なんて言ったりしますが、世界中で38億人のネットユーザーが存在する中で、1日に平均32億回ネット検索がされているようです。
※2012年にGoogle Zeitgeistが言及。それ以降は公表していない
少し古い情報ではありますが、1日の検索回数が30億超えには驚きですよね?
その検索行為そのものがエコに繋がるとしたらどうでしょう?
今回は、ある検索エンジンを使うことで誰でも手軽に環境保全活動へ貢献できるアプリをご紹介します!
Ecosiaはドイツ生まれの検索エンジン。
検索で発生した広告費用の利益を一部、植林・森林再生活動を行う非営利団体に寄付しています。

ご存じの通り、ドイツは世界の国のなかでも環境活動への意識が高い国として有名。
学校の教育方針に「自然と環境に対する責任感を身につける」という指針が追加されているほどなんですね!
例えば、
・屋上緑化⇒緑地に家を建てるなら屋上を花壇にするなどして埋め合わせをする
・市内駐車料金を高く設定⇒マイカー利用を減らすことで渋滞とCO2の削減
・「プファンド」というデジポットの制度⇒ペットボトルや缶・ビンなどの飲料を買うと、先に保証金を払うシステム(飲んだ後に容器を返せばお金は戻る)
などなど、かなり本気で取り組んでいるんです!
そんなドイツ生まれのEcosiaの仕組みはどういうものなんでしょう???
Ecosiaで検索した結果は、Microsoftの検索エンジン『Bing』から提供されていて、Bingの検査結果プラス、Ecosiaのアルゴリズムを採用しているそう。
で、ここからが本記事のメイン部分。
Ecosiaで検索をすると、およそ0.5ユーロセント(0.005 EUR)の利益が発生。1本の植樹に必要な金額がおよそ22ユーロセント掛かるので、
22÷0.5=45
つまり、45回の検索で1本の木を植えることが出来るんです!!
検索での利益は広告費から発生するので、Ecosiaはその広告からの利益8割を植樹・植林活動に使用しているんですね。
「Ecosia」の公式Twitterでは2021年4月実績として、およそ700万本の樹木が植樹されたという財務報告を公表しています。
以下、Ecosiaのブログでは国ごとの活動実績が掲載されています。

さて、私たちが普段使っている検索エンジンをEcosiaに変えるだけで、世界中に木を植えることが可能になります。
今日から取り入れられる、日常的にEcosiaを使う方法をご紹介します。
EcosiaへアクセスしてGoogleの拡張機能へ追加する方法。
普段使っている検索窓に「Ecosia」と検索。cheromeの拡張機能を使います。

スマホでEcosiaを使う場合は、アプリをインストールする必要があります。もちろん無料^^
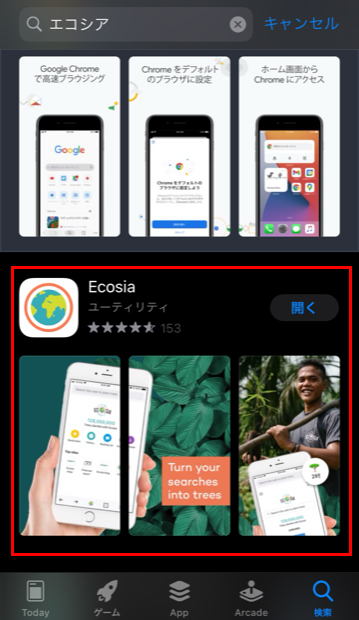
使いやすいように、スマホのドックへ追加。

「せっかく追加したんだから使ってみないとな!」
ってことで検索しまくる。
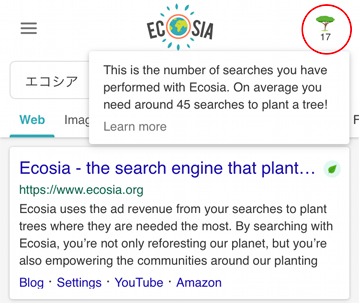
検索結果の右上ツリーのアイコンの下に、累計検索数が表示される。
たしか45回の検索で木を1本植えることになるから、あと28回ってことですね♪
環境保全活動と聞くと一見ハードルが高そうなイメージですが、検索なら一日に何回もするのでそこまで難しいことはありません。
45回の検索につき1本の植樹を行うので、私は既に1回植樹をしたことになりますね!!
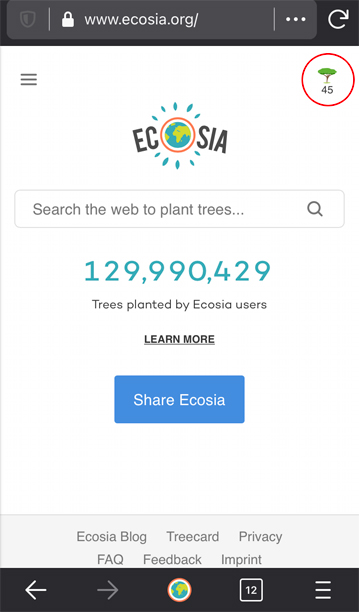
いかがでしたか?
普段行っている“検索”という行動を変えるだけで、自然と環境保全活動に協力していることになるので、カンタンに出来るエコですよね!
近年では、環境問題について日本でも関心が高まってきています。
エコバッグ、マイボトル、マイストローなど私たち個人で出来る環境保全もありますが、企業による経済活動のなかでも、CO2排出を削減し、それでも排出されるCO2の数値を知り、その分の埋め合わせをするという『カーボンオフセット』という考え方が誕生しています。
Ecosiaの植樹5,000万本によって、およそ250万トンものCO2が除去されるそうですので、これも『カーボンオフセット』の例ですよね。
日常で取り組める環境保全活動は他にもたくさんあります。
環境問題と真摯に向き合いながら、私たちの住む地球を守っていきたいですね^^
![]()
![]()
この記事を書いたひと:福田 聡樹(ふくだ さとき)
株式会社プロトソリューション Webマーケティング部所属。自社ホームページ編集長。ブログ/インタビュー/動画などのコンテンツを使って、プロトソリューションのサービスやタレント情報を発信しています。
好きなもの:爬虫類全般、本のにおい。

“企業文化を何より大切にした組織を創り、お客さまを支援したい”という想いから誕生した「SENZOKU LAB.」にて、導入いただいている企業さまの事例記事を公開いたしました。
今回の導入事例では、ヤフー株式会社様をご紹介しております。
外部のパートナーと一緒にビジネスをつくっていく形を模索していたとおっしゃるヤフー様に、導入後の良かった点や決め手などのインタビューにお答えいただきました。
ぜひご覧ください。
「SENZOKU LAB.」は単なるリソース提供ではなく、お客さまの目指すビジョン、大切にされている価値観(フィロソフィ)を理解したカルチャーフィットする組織をお客さまと一緒に創りあげ、成長させていきます。
「SENZOKU LAB.」サービス紹介ページはこちら
オンライン相談予約を随時受付中です。
みなさん、はじめまして。
プロトソリューション仙台本社の進藤です。
今回は、私の仕事に対するマインド・スタンスを、当社人事の西野にインタビューしてもらいましたので、ほんの少しご紹介させていただきます。
最後までご覧いただけましたら幸いでございます。
2005年04月 – 2016年09月
株式会社アイソリューションズ入社
Webエンジニアとして、プログラマー、システムエンジニア、プロジェクトリーダー、プロジェクトマネージャーを順に経験。宮城県地場企業様から、首都圏大手企業様まで、大小多種多様な企業様のソリューション開発・ニアショア開発に従事。
2016年10月 – 現在
株式会社プロトデータセンターと合併し、株式会社プロトソリューションへ商号変更
仙台開発事業部の責任者として事業を統括、事業部戦略立案を中心に、ブランディング、リクルーティングなど、仙台本社に関わる取り組みを推進。現在は、AIテクノロジー推進室仙台を設立し、前述に加えて、システム開発(Web系)は勿論のこと、プロダクト開発(新規事業企画・SaaS製品開発)、R&D(AI研究開発・高度IT人材育成)、HRBP(人事戦略考案)、この4セクションの統括マネージャーに従事。
特別なことはなくて普通だったと思うけど(笑)ただ、とにかくこだわってモノづくりをしていたのと、自分なりのポリシーは色々あったと思う。ITに興味がない、、、それだと語弊があるね(笑)ITに興味がないというよりは、IT以外のコトにも興味を持つようにしていたかな。そこは単純で多種多様なお客様(業界・業務)がいらっしゃるので、必然的にIT以外のコトも、お客様程とはいかないまでも知って、しがみついていかないといけないし、ITに没頭していれば、良いモノを作れる!っていうのはまかり通らないよね。だけどITは、世の中で最も夢のある、そして素晴らしい、最高の手段だとずっと思ってる。
それは今も変わらなくてデータだね。お客様からオーダーをいただくシステム開発は、データをインプットして、アウトプットすること。一般的なWebサイトは、データを出し入れするためのいわばツールみたいなもの。データはお客様にとって貴重な資産で、データがあれば何かを創造できるかもしれないし、何かの方法が見つかるかもしれない、お客様の未来に繋がるはずだから、データだけは絶対に守らなきゃいけない!勝手にデータドリブンみたいな感じで必死だった(笑)だから、テーブル設計や、ER図のレビューなんかは、もう戦争(笑)これ!っていう答えがある訳じゃないから、エンジニア同士の意地と意地のぶつかり合い、バッチバチ(笑)
あとデータで言えば、後輩エンジニアにも、SQLから先に作ろう!って教えてた、逆に画面、Web、SQLの順で作ってしまうと、早く画面の動きが見たくて、SQLをおろそかにしちゃう、、、複雑になりがちで、カスタマイズ性を左右するのもSQL。それから、開発コストや、ランニングコストを下げたり、不具合解消のスピードと質を上げるのも、テーブル構造のデキが大きい。例えばデザインはお客様と密に詰めてアウトプットするけど、データはお客様が介入されない我々エンジニアが単独で完全に責任を追う唯一の領域だから、こだわりを持って当たり前。
当たり前と言えば、どこまでいっても、自分なりのポリシーの軸は「ABC(当たり前の事をバカになってちゃんとやる)」かな。デスクを綺麗にしてっ!・・・なんてこと、よく言ってるでしょ(笑)

チームメンバーが何かを成し遂げてレベルアップをした時。初めて後輩が出来た頃から、自分よりも、後輩にベクトルが向いていたかな。それは、当時の先輩が仰っていた言葉がきっかけで「後輩は先輩を超えるもの、先輩の教えプラス自分があるから超えて当然」って言われたのを今でも覚えていて、それが大きな影響だね。
チームメンバーが笑っていない時は、すごく不安になる(笑)仕事でも何でも、ポジティブに楽しんで取り組んだ方がいい。その方がジブンゴトとして考えることもできるし、やり甲斐も、余裕も生まれる。なんなら失敗だって成長の糧なんだって思えるよね。当然、仕事上は、お客様がいらっしゃってローンチまでのプレッシャーもあるし、自分が成長できないストレスだってある、大変な事も多いかもしれないけど、朝起きた時、今日も頑張るぜ!って心躍る、そんなポジティブフルなチームがいい。
フロア散歩。普段、彼らから私に用事がある時って、決裁やら報告、もしくはネガティブな相談事・・・マネージャーって孤独なのよ(笑)だから、この時間って決めて散歩してる。
「ウィ!調子どう?」だけ(笑)特に自分が見させてもらってる部署は若手が多くて、何気ないコミュニケーションでも成長を感じられて、素直にすごいじゃん!って感心するし、同時にチームが上手く機能している安心感も得られる。特にスペシャリストの連中なんかは動きも考えも面白いよ。フロアにはポジティブなニュースがたくさん落ちてるから、それを拾い集めてる感じだね。
すごくシンプルで、課長、部長、役員みたいな現場からは少し離れていて、ブラックボックスな会議に参加するような人達に声を掛けられると、嬉しかったし、頑張ろう!ってモチベーションになったり、良い刺激をもらえていたから、そうしてる。
・・・(笑)
当社のサービス < ラクネコ > の担当者に「ウィ!調子どう?」って言ったら「只今、リリース中です!」って即答されて「あ、ごめん」って言ったよね(笑)それから彼には「今、リリース中?」って声を掛けるようにしてるよ(笑)
組織を運営する中で意識しているのは、何よりもメンバーの成長が一番。ヒトがモノを創って、モノがコトを生むんだから。更に欲を言えば、テクノロジーとアイデアの中に自分達が居るような環境とか風土も創っていきたいね。あと、普段の振る舞い的なことでいうと3つあって、①自分という存在が常に適度なプレッシャーであること、②自分が一番のアイデアマンであること、③メンバーへの感謝を常に持ち続けること、この3つだね。
特にない(笑)トップダウンで、あーして、こーして、っていうのは響かないから、自分らしく彼らは彼らなりのマネージメントをしていけばいいと思う。
強いて言えば「自分以外はお客様」精神かな。チームや、部署を率いるということは、カタチ上は自分が一番上に立っているようで、実は一番下。メンバーありきで自分がいて、メンバーに助けられていることを常に忘れてはいけないからね。

世界平和。すごくスケールの大きい話かもしれないけど、世界には困っている子供達がたくさんいるから、ちょっとでもチカラになれればいいと思っている。未来は子供達が創っていくんだから、子供達の夢が広がる各々の社会を創造する義務が現社会人にはあるよね。
世の中には数年後の将来を描き、それをカタチにして社会を変えている企業や、経営者の方々がいらっしゃって、生活を支える重要なインフラになっていたり、人々をアッと驚かせるアイデアで時代を牽引したりと、それだけで十分な社会貢献なのに、営利だけではなく、サステナブルな視点も含まれている、本当に凄いこと。このような大きな影響力を持つ企業や、経営者の方々が、世の中の10%だとしたら90%の人々は、小さなことでも何か一つ!後世に残していくことが重要だと思う。そこに、エンジニアとか、プロフェッショナルとしての社会貢献ということにこだわりはなくていい。
いつの日かくる社会人の終わりに、心の底から満足できていればいいんじゃないかな。
「Re:Jomonプロジェクト」は、東日本大震災から十年の節目を迎えて、地域の皆様に際して、何か貢献したいという想いで発足したプロジェクトだから、やるべきミッションは違うけど、ビジョンは同じだね。このプロジェクト通じて地域が活性化していって、東北から世界にちょっとずつでも波及できれば、もしかしたら届くかもしれないね。
このプロジェクトは、まだまだ道半ばだけど、本当にありがたい機会をもらえたと思ってる。ぼんやりとしていた夢がチャンスというカタチになって、目の前に来るとは思ってもなかったし、それほど、当社にはチャレンジしようとするマインドやカルチャーがあるってということだよね。
本当に器の広い、そして恵まれた会社で働けているって本気で思うよ。

私達、プロトソリューションは、これからもバッチバチと成長して参りますので、もし、この記事を見て、ITへ挑戦してみたい!当社で働いてみたい!と感じていただけたら幸いでございます。
最後までご覧いただき、ありがとうございました。
ソリューション開発部仙台に所属している内藤と申します。現在はグループ会社の基幹システム開発を行っております。
もともとはECシステム関連を得意としておりましたが、ECシステムにかかわらず、システム構築全般をこなしてきました。
自己紹介でも書きましたが、グループ会社の基幹システム構築に携わっております。もともとはその会社で行っているEC販売に関連するシステム構築のお話を頂き、そこから拡大して会社全体を担う基幹システムを構築したいとのことで、毎年少しずつ機能を追加して現在は会社のほとんどの部署をまかなうシステムの構築をすることができました。
システムを構築する手順としては、相手先の担当者との要件定義(どんな物を作成するかを決める)から始まり、基本設計、詳細設計、実装、単体テスト、結合テスト、システムテストと各工程を経て最終的に完成に至ります。
そのような手順を踏まえて作成された基幹システムですが、基幹システムと一言でいってもどのような物か想像しづらいのかと思いますので、少しご紹介します。
会社内の各部署によりさまざまな機能が存在します。
社内だけではなく、外部のシステムとの連携も行い、業務にかかるコスト削減を目的としています。
・販売系部署
- 受注データの作成
- 各種外部ECサイトへ接続し受注データの連携(楽天、Yahoo!、Amazon、他ECサイト)
- 手動での受注データ作成
- 仕入担当部署への発注データの作成
- レジシステムとの連携
- タブレットを利用しお客様に記載頂く為の入力フォーム
- お客様のシステムとのデータ連携
・管理系部署
- 発注データの作成
- 仕入データの作成
- 商品データの管理
・物流系部署
- 配送商品の物流会社との連携
- ハンディターミナルを利用した商品のチェック処理
・経理系部署
- 販売、仕入にかかる入金の管理
まだまだ他にも機能があり、また今後も拡張して行く予定となっています。

システムのベースはJava言語を利用したWebシステムとなっていますが、外部との連携、実現したい内容、プラットフォームにより、利用言語を変更しています。
| プラットフォーム | 利用言語 |
|---|---|
| Web | Java |
| Android | Java |
| ハンディターミナル | VisualBasic.NET |
また、これらのシステムを作ったとしても動かすためのサーバーが必要となります。
サーバーを動かすということは、セキュリティやネットワークなどのインフラ関連も重要になってきますので、システム構築には様々な知識が必要となります。
| インフラにかかわる知識 | |
|---|---|
| OS | Linux、Windows |
| Webサーバー | Apache、nginx |
| FTPサーバー | vsftpd、IIS |
| データベース | Oracle、PostgreSQL、MySQL |
| ネットワーク | ネットワークセグメントの設計、LB、IPS/IDS |
| クラウド | AWS |
このように、一つのシステムを作ることで新しい知識が増える喜び、成長を実感することができ、
またお客様によろこんで頂けると言葉では言い表せないほどの感動を得ることができます。
システムを構築する上で大事なことは、お客様の要件を聞き(要件定義)、実際には何を実現したいのかを把握し、無駄をそぎ落としつつシステムに落としこんで行くこと(設計)だと思っています。
言われたままシステム化を行うと、完成後に「こういうのではなかった。。」ということが起きてしまいます。(私も若いころにそういうことも経験しました。。)
技術を追い求める事も大事ですが、システムエンジニアとしては、ヒアリング力、提案力も大事な要素となります。
これらは、一人の力で解決できるものではなく、人それぞれ長所、短所があるように得意不得意のあるメンバーが集まって、チームで解決していくことでより良いシステムの構築ができるものだと思っています。
技術が好きな方、話すのが好きな方、考えるのが好きな方、それぞれで活躍の場がありますので、
一緒にシステム構築をやってみたいと思って頂ける方がいらっしゃいましたら、是非ご応募頂きたいです。
生産人口の減少問題を、データと AI で解決する 株式会社プロトソリューション(本社:沖縄県宜野湾市、代表取締役社長:白木享)は、運営するクルマ情報メディア「グーネット沖縄」およびクルマ情報誌「グー沖縄版」において、中古車の車両状態情報を開示するサービス「グー鑑定」の提供を、2021 年 7 月 1 日(木)より開始いたします。

沖縄における「グー鑑定」は、「グー鑑定」加盟店で販売される中古車に対して、プロの鑑定師が中古車の車両状態を鑑定し、「グーネット沖縄」および「グー沖縄版」でその情報を開示するサービスです。第三者機関のプロの鑑定師によりチェックを行い、公正に評価を定めます。
車両鑑定は、特定非営利活動法人日本自動車鑑定協会(東京都大田区、理事長:剣持 純也、以下JAAA)が、(1)外装(2)内装(3)機関(4)骨格 の 4 項目を統一検査基準により実施し、その車両に鑑定証を発行致します。
<サービス開始日>
2021 年 7 月 1 日(木)
<サービス内容>
・ JAAAが、(1)外装(2)内装(3)機関(4)骨格 4 項目を統一基準により鑑定し、鑑定証を発行
・ プロトソリューションにより車両状態情報の開示(Web サイト「グーネット沖縄」、情報誌「グー沖縄版」)
・ 「グー鑑定」加盟店で、鑑定証が発行された中古車を販売
Point1 【公正】 第三者の鑑定師がチェック!
第三者機関のJAAAの鑑定師が中古車を鑑定。プロが一台一台チェックします。
Point2 【納得】 外装・内装・機関・修復歴について評価!
外装・内装・機関・修復歴の 4 項目について鑑定を行っています。
見た目からでは判断がつかない箇所も入念にチェックしています。
Point3 【分かりやすい】 鑑定証付き
鑑定した外装、内装、機関、修復歴のそれぞれについて評価を定めます。もちろんメーター改ざん等があれば鑑定証は発行されません。

沖縄のクルマ情報を網羅しているクルマ情報メディア・クルマ情報誌。
中古車情報や最新のクルマ情報が盛りだくさんの情報誌「グー沖縄版」と、お近くの販売店情報や様々なイベントをリルタイムで更新しているクルマ情報メディア「グーネット沖縄」でクルマ選びのサポートをいたします。
https://ok.goo-net.com/
プロトソリューションは、株式会社プロトコーポレーション(本社:名古屋市中区 代表取締役社長:神谷 健司)の100%出資のグループ会社であり、「生産人口の減少問題を、データと AI で解決する」ことをミッションとするソリューション企業です。沖縄県宜野湾市に本社を置き、沖縄のクルマ情報「グー沖縄」や不動産情報「グーホーム」などのメディア運営をはじめ、デジタルマーケティング事業、IT インテグレーション事業、ユーザーメディア事業、コミュニケーションサポート事業、人材支援事業の5つの事業を展開しています。
代表者 :代表取締役社長 白木 享(しらき とおる)
本社 :沖縄県宜野湾市大山 7-10-25 プロト宜野湾ビル
設立 :2007 年 4 月 3 日
事業内容:デジタルマーケティング事業、IT インテグレーション事業、ユーザーメディア事業、コミュニケーションサポート事業、人材支援事業
URL :https://www.protosolution.co.jp/
【本リリースに関するお問い合わせ先】
㈱プロトソリューション(www.protosolution.co.jp)メディア事業部 玉城久子
沖縄県宜野湾市大山 7-10-25 携帯:090-9262-4102 FAX:098-890-6713
Mail:h-tamaki@protosolution.co.jp
ソリューション開発部沖縄に所属している星川と申します。2011年に入社しまして前職の経験を活かしPHPを使ったサーバーサイドの開発をしていました。
その後、運用担当しているWebサイトのSEO担当を経て、現在は社内マーケターとして沖縄県の不動産情報を紹介するポータルサイト「グーホーム」や受付クラウドシステム「ラクネコ」のサイト分析や広告運用管理、コンテンツ管理などの業務を行っています。
プロトソリューションは親会社であるプロトコーポレーションから依頼される業務が多く、顧客を理解した付加価値の高いサービスを提供することに長けた人材が多くいます。ただ「どうすればサービスを認知してもらえるのか」「興味を持ってもらえるのか」などの考えは現場ではあまり必要とされておらず意識されていませんでした。
自社サービスのマーケティング業務をしていく中で「社内にもっとマーケティングの知識を業務に取り入れてもらいたい」「もっとマーケティングを意識して業務に取り組んでもらいたい」と思うようになり、さまざま活動してきましたのでその活動のご紹介をさせていただければと思います。
サイト分析を任されるようになり会社に資格取得奨励制度があったこともあって、基礎となる知識習得を目的にWeb解析士の資格の取得を目指すことになりました。
Web解析の手法を体系的に学べるのかなと考えていましたが、資格の勉強をする中でデジタルマーケティング大枠の知識が習得でき、マーケティングの理解が深まるとともにマーケティングに対して興味を持つようになりました。
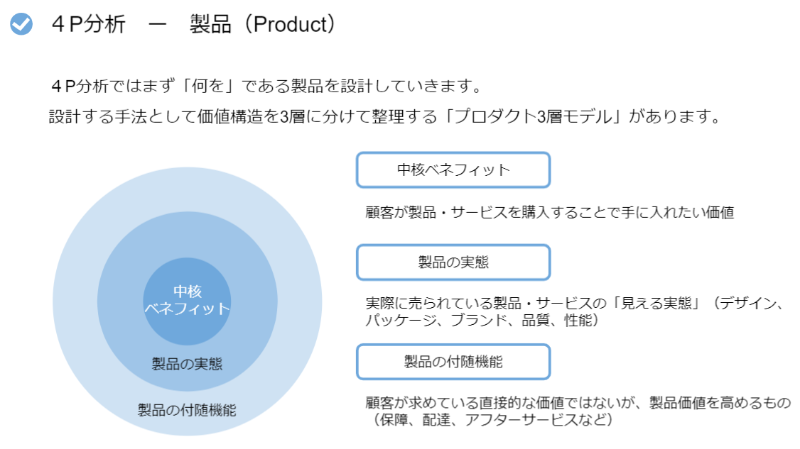
マーケティングというとプロモーションだったり広告だったり集客の部分を想像していたので、PEST分析やSTP分析、4P分析といった市場理解や顧客理解の概念が理解できたときは、今までの視野の狭さを反省するとともにモヤモヤしていた視界が開けたように感じました。

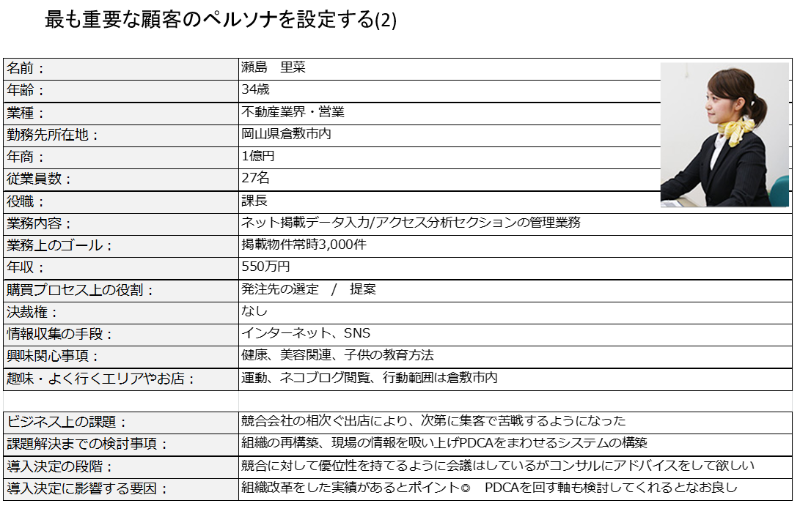
マーケティングの重要性は理解したものの社内にマーケティングを専門としたチームが存在していなかったため、チーム構築を目的に社内で有志を集め勉強会を開催することにしました。
幸い募集をかけたところ社内の色々な部署の方から参加したいとのお声をいただきまして、沖縄県内でマーケティングを積極的に取り組んでいらっしゃる株式会社アザナ様へお声がけをさせていただき、合同でマーケティングの勉強会を開催する運びとなりました。
会場はプロトソリューションの会議室と、アザナ様が運営されているレンタルスペース「epic」の交互で実施し、いつもと違う環境、メンバーで新鮮な気持ちで取り組むことができました。




勉強会はマーケティングのフレームワークを軸にした、売れる商品とは何か、売れる仕組みは何かを理解していく座学を行いました。
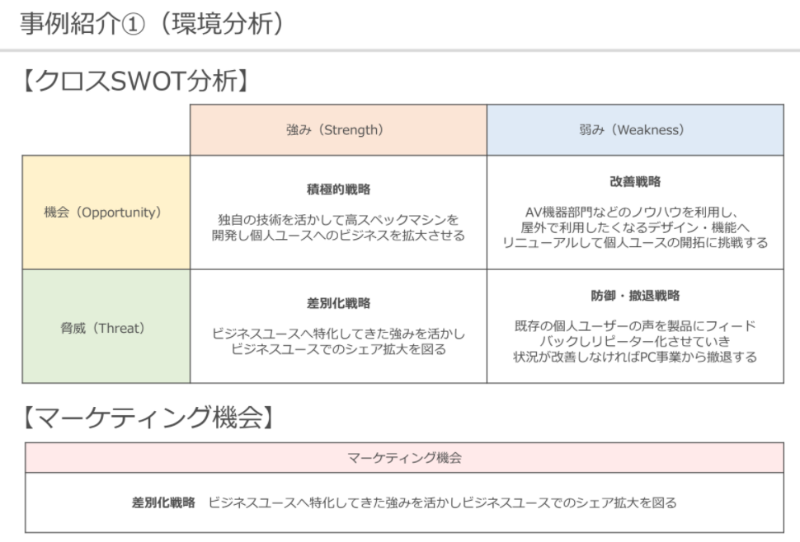
その中で自ら考えアウトプットする癖を付ける必要があると考え、成功企業のマーケティングがどう行われていたのかをフレームワークに落とし込み理解を深めていきました。
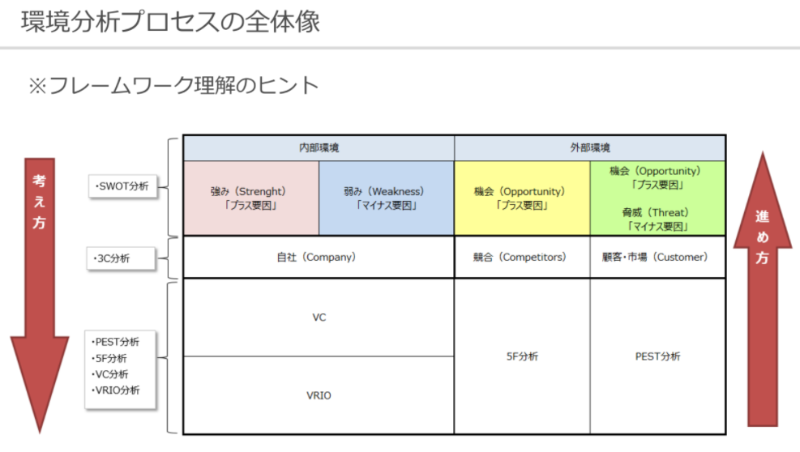
カリキュラムは以下の流れで進めていきました。
1.座学によるインプット
2.成功企業のマーケティングをトレース(フレームワークの使い方理解)
3.お題となる商品のマーケティング手法をフレームワークを使って分析
4.チームごとに考えたマーケティング手法の考察を発表
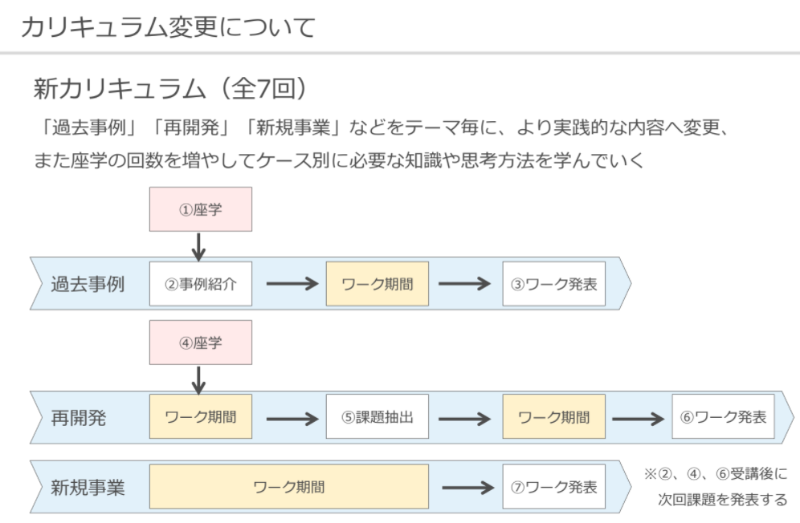
全6回(約2ヶ月)の勉強会を通して参加者のマーケティング理解が深まったことはもちろん、運営した私も理解が深まり大変有意義な勉強会だったと思いました。

この勉強会で作成した資料は、プロトソリューションの新入社員向けの企業研修資料に編集し活用しようと考えています。
残念ながらちょうど進めていたタイミングで新型コロナウイルスが発生してしまいまだ実現できておりませんが、どの業務に就くことになったとしても必要な知識だと思いますので実現に向けて進めていければと考えております。
研修のデモとして、社内勉強会の実施は行いました。



勉強会をしてから気付いたことですが、勉強会で取り組んだ成功企業のマーケティング手法をトレースする勉強方法はすでに更にブラッシュアップした形で取り組まれている方がいました。その方は勉強会を合同で実施したアザナ様の親会社であるブランディングテクノロジー株式会社様のCMOの黒澤様だったという奇跡みたいなことが起こりました。
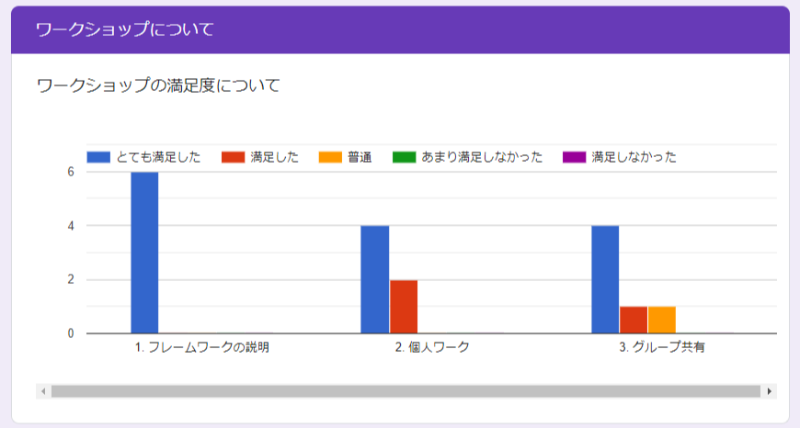
ちょうど社内の業務やプロジェクトにマーケティング視点を入れて事業をグロースさせられないかという取り組みをしようと考えておりましたので、社内のマーケティングの現状を認識するべく黒澤様を沖縄に招聘しワークショップを実施していただきました。


参加者の方からは大変満足したとのお声をいただき、マーケティングの重要性や取り組みの具体的な手法など理解を深める機会になったと感じました。
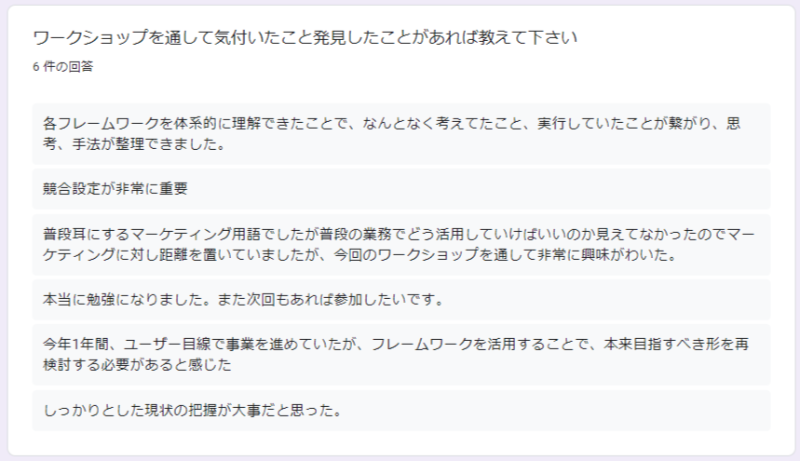
ワークショップ実施後、ラクネコのプロジェクトからお声がけをいただき現在の業務に繋げることができています。
次に実施したこととして、部内の経営視点の理解促進を目的として管理者メンバー向けにオンラインで実施できるビジネスボードゲーム型の企業研修「マーケティングタウン」を行いました。
限られた資金を元手に販路を拡大し、マーケティング戦略を立ててユニコーン企業を目指すというルールですが、とても短い時間制限の中で的確な判断をし続けないといけないというのはリアルに通ずるものがあり、実際の経営の難しさを疑似体験できるいい経験になりました。

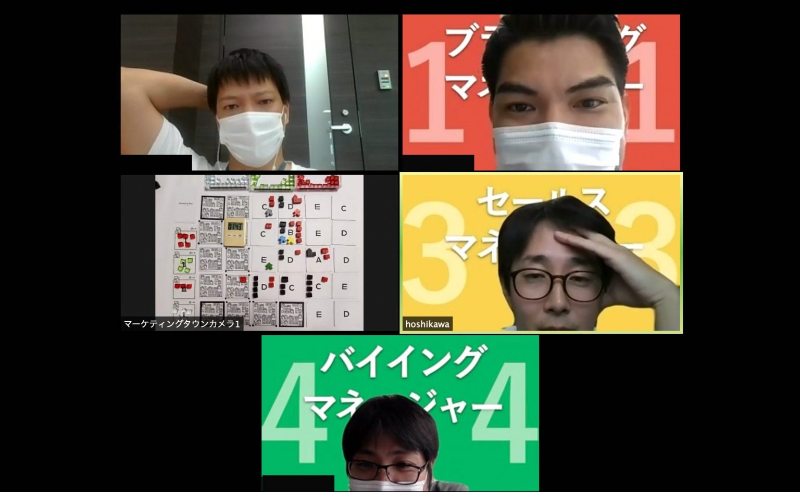
惜しくもユニコーン企業には成れませんでしたが、機会があればまたリベンジしてみたいと思っています。
また、新型コロナが収束したタイミングで県内のマーケターや管理者層に向けたイベントとして、実際に集まってマーケティングタウンを開催をしてみたいと思っています。沖縄県内のコミュニティと関わることがなかなかありませんので、その機会になればと考えています。興味ある方はぜひご参加いただければと思います。
次に現在も継続して実施している活動として社内LTを毎月開催しています。コロナ禍で自粛要請が多くストレスが多い世の中になっていますが、沖縄在住の身として今まで距離的な問題で参加ができなかったセミナーが自宅で受けられるという恩恵を受けられるようになり、そこでインプットした情報を社内共有したく始めた活動となります。
毎月テーマを決めてGoogle Meetを使ってのオンライン生配信で実施しています。15時に休憩時間がありますので、そこで気分転換に聞いてもらえたらと思い15分のショート配信をしています。
おかげさまで毎回多くの方に視聴をいただき「面白かった」「参考になった」「業務に活かしてみます」など嬉しいフィードバックをいただけています。
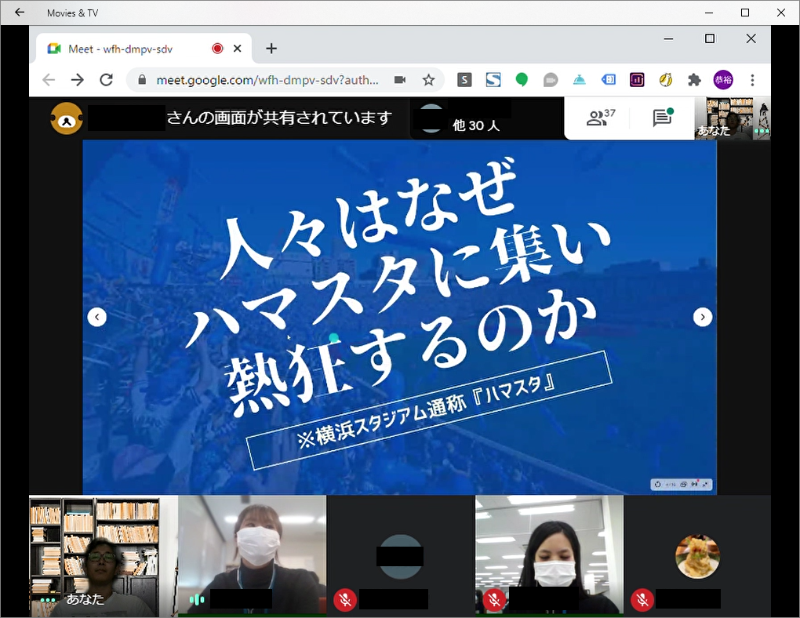
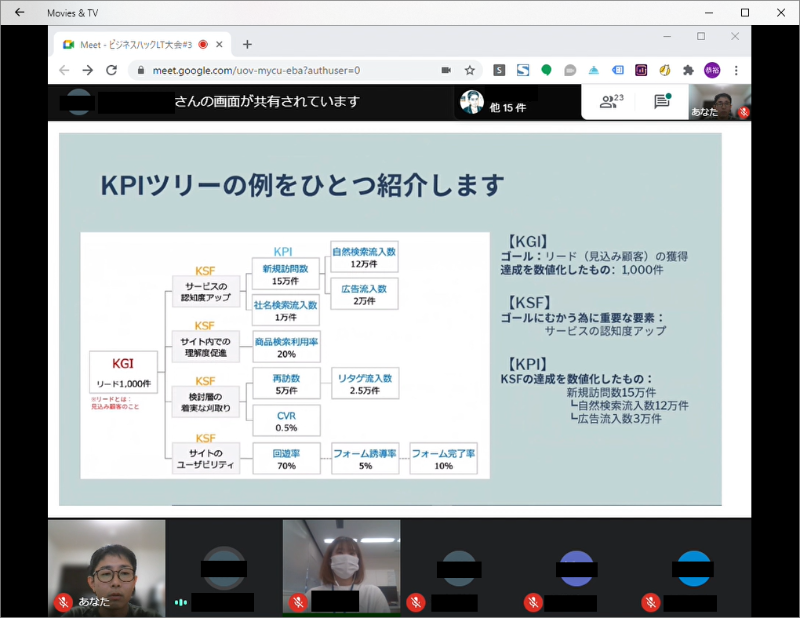
今後も情報発信の機会と私自信のアウトプットの練習として継続していきたいと考えています。要望などあれば特定のキーワードやツール、手法についての解説もしていきたいなと考えています。
以上がこれまで取り組んできた内容になりますが、これから実施していきたい取り組みとして社内向けのe-Learningを構築したいと考えています。
マーケティングと言っても求められているもの、受け取り方はさまざまで、マーケティング担当者になっても何を指標に進めていけばいいのか迷ってしまうことが多いと感じています。
今後マーケティングを専門とするチームを構築していくにあたり教育資料として運用できるような5分程度の動画をまとめた社内e-Learningを構築していければと考えています。また、実際に業務で困った時に参照できるツールとしても活用できればと思っています。
SEO対策やキーワード選定、広告の費用対効果など各部署のマーケティング担当でない方でも気になった時に気軽にアクセスできるツールを目指して今期構築を目指します。
プロトソリューションは自社メディアやSaaS事業など新しい事業への挑戦をし続けています。それに伴い社内でのマーケティング人材の需要はこれからも増加していくと考えています。
小手先のテクニックだけではなく、顧客を理解して必要な人に必要なサービスを届けられるよう、社内のマーケティング文化の発展へ向けてこれからも取り組みを続けていきます。
マーケティング業務の経験があり沖縄でスキルを活かしたい方や、マーケティングに興味があって挑戦してみたい方はぜひ採用までお問合せください。一緒に沖縄発のマーケティングを盛り上げていきましょう!
ご応募はこちらから。ご連絡をお待ちしております。
最後まで読んでいただきありがとうございました。
こんにちは。編集部の福田です!
今、Z世代に大人気の『Muze』というアプリをご存じですか?
なんでも、感覚的に遊べるというのがハマる理由なんだとか。
今回は、私Y世代の福田がMuzeを実際に使ってみたうえでのレビューをまとめてみました。
この記事を読めば『Muze』がどんなアプリなのかが、“感覚として” 分かる内容になっています。
是非最後まで読んでくださいね♪
参考までに
Y世代:1980年~1990年後半生まれ。デジタルネイティブ。ブランド志向。空気を読む。話好き。ムダを楽しむ。理想を求める。
Z世代:1990年後半~2012年生まれ。SNSネイティブ。本質志向。多様性を重視。接客が苦手。ムダを省く。リアルを求める。
※世代の定義については様々な議論がされているので必ずしもそうではない
結論から言うと、面白い!
チャットアプリと聞いていたが、少し違う。
テキストや写真、スタンプに動画などを真っ白い画面に貼っていくんだけど、これまでのチャットアプリとは違って、対話する相手と自分とで画面が左右に分かれているわけでもなく、誰のターンといった概念もない。
お絵かきできる日記みたいな感覚で、自由度はめちゃくちゃ高いのが特徴。
これまでに、ありそうでなかった感じ。
ひと言では言い表せないので、実際のキャプチャを使って説明していきます!
さっそくMuzeを開くと、画面が真っ白!
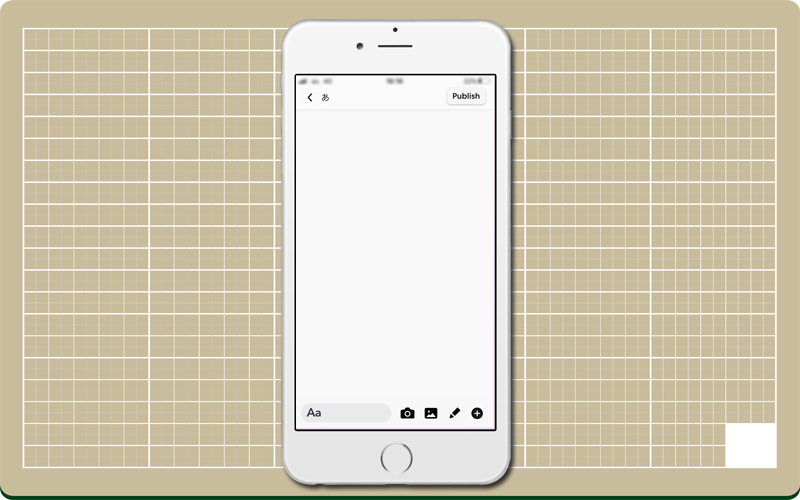
インターフェイスは、普段触り慣れているチャットアプリと大差はない。
まずは試しにとテキストをタップ。
フォントの種類や装飾、配色の多さに戸惑う。
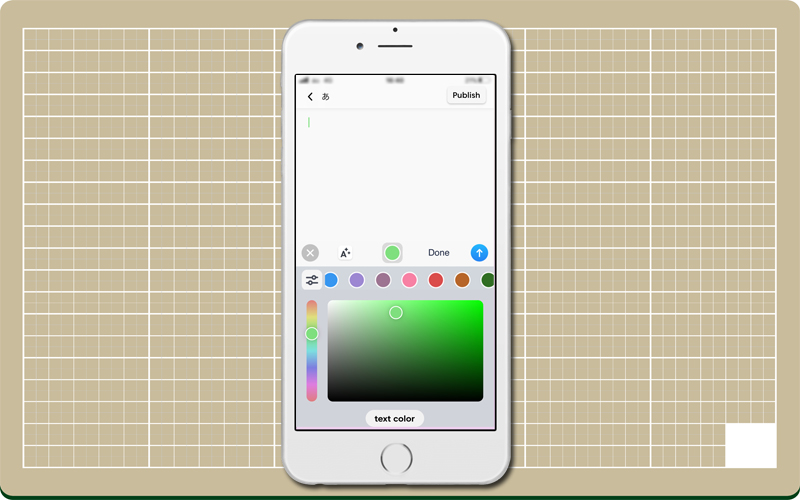
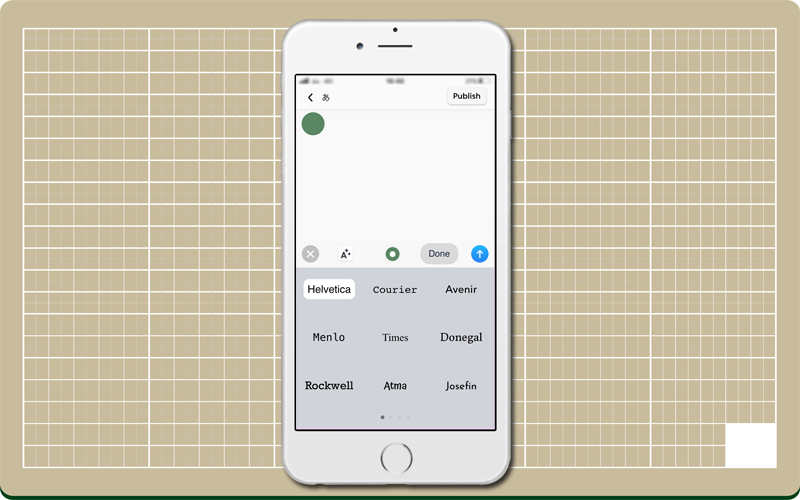
適当に書いてみるが、いつもと様子がおかしい。
なんだなんだ!?
テキストを移動できたり、拡大できたり、普段のチャットアプリと違ってどう使えばいいのか分からない。。

しかし私もデジタルネイティブ世代の端くれ。
3分くらいあちこち触っていると、
はいはい、感覚で分かってきましたよ。
「言葉ではなく心で理解できた!」

テキストの形、大きさ、色などを自由に選べるので、適当に並べてもなんか派手さが出る。
画像も同じ様に移動や拡大といった操作が感覚でできちゃう。
なんか凄く自由過ぎて、不安になるなー。
まっ、正解はないのだろう。気にしない気にしない。
1人で遊ぶのも飽きたので、他ユーザーとやりとりしてみる。
Muzeも従来のチャットアプリみたいに「友達かも?」の機能がついていて、私の電話帳にある同僚らしき人物がリストアップされる。(リストアップされるには相手にもMuzeアプリをダウンロードしている必要がある)
そして、ちょっとした遊び心なのか、左上のmuzeロゴをタップすると、ロゴの色やテクスチャが変わるようになっている。
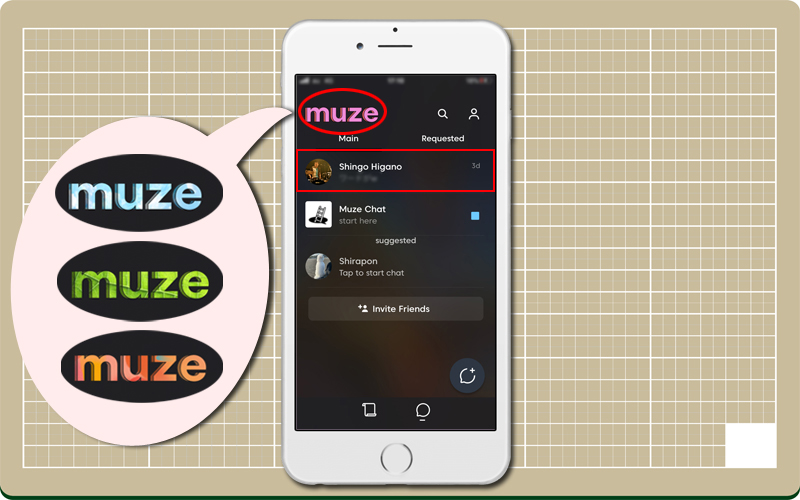
友達申請をすると相手も暇だったのだろうか、即レスが返ってきた!
2人で使うとどうなるんだろう。。?
私の好奇心が湧いたと同時に相手からテキストと写真が貼られてくる。
おぉ!興奮してつい英語になってしまう。w(゜o゜)w
使い方が分からない同士でやりとりをすると、あっと言う間に真っ白なキャンバスがカオスな状態になった(笑)
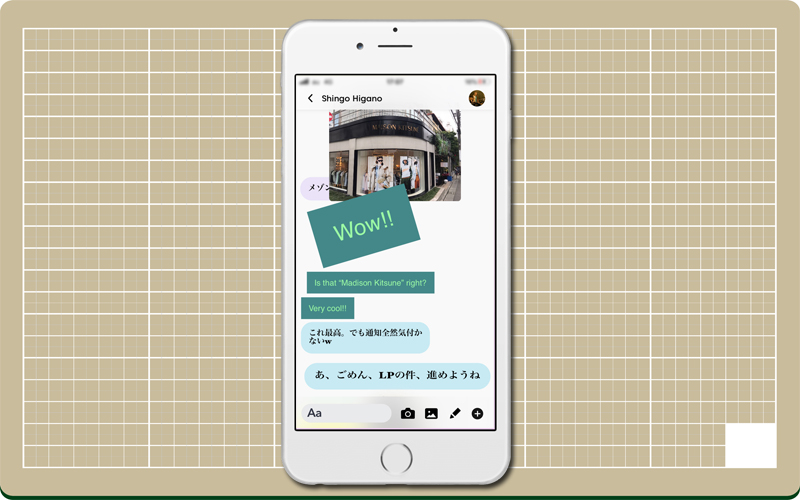
相手からのコメントや写真の上に、自分が書いたテキストや写真などを上書き配置することが出来る。
キャンバスのどこに書いてもいいという自由度の高さは、逆に何についてのレスなのかが分かりにくくなるので、その辺は上書き配置でカバー。
そのほか、フリーペン機能もついているので、お絵描きしたり何かを説明するときなどに使えそう。
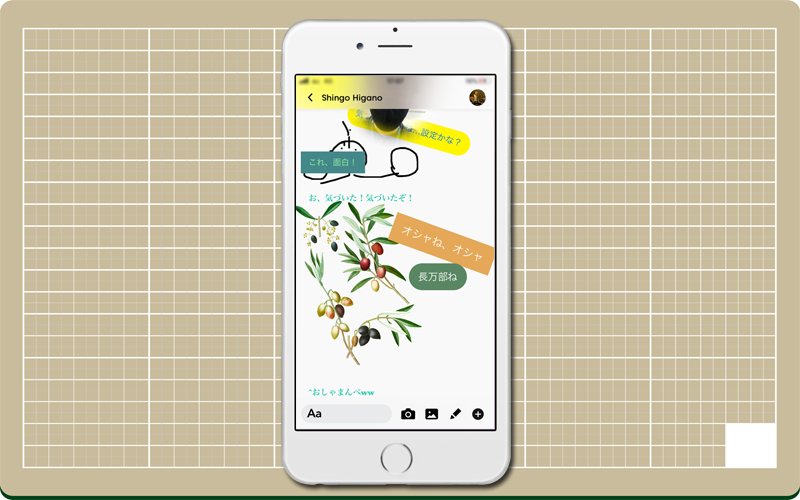
ごちゃごちゃカオスな感じが、かえってアーティスティックに仕上げてくれる気がする。
やりとりしたあと、振りかえって見るのが楽しみにもなりますね♪ 1つの作品の様です。
感覚でのやりとりは何も考えないで良い分、受け手の捉え方によって伝わり方が変わるので、『伝える』というコミュニケーションにおいては従来のチャットアプリのほうが使いやすいと言える。(ガチ感想)
しかし、Muzeの良さは感覚的にやりとり出来るからこそ、枠に捕らわれないクリエイティビティの高いコミュニケーションが可能になる。
今Web上では、一生かけても消費しきれないほどのコンテンツが溢れていて、有益な情報の取捨選択を瞬時に判断しながらも、いかに無駄を省き生産性を高めていけるかということが重要視されている。
動画を倍速で見たり、ながら学習ができる音声メディアといったいわゆる「時短」が注目されているのがその証拠だろう。
そんな中、MuzeがZ世代に人気なのは、前述した内容と矛盾するようだがその “分かりにくさ” “伝わりにくさ” にあると使ってみて感じた。
“伝わりにくい” から生まれる「あはは、何それ?」と言ったコミュニケーションから新しい話題が派生して、そこから面白い発見が生まれる。
なんでもかんでもWeb上で調べれば解決できる時代に生きる若い世代にとって、
何が起こるか予測できないMuzeは、“新感覚なコミュニケーション” に触れられる場所なのかも知れないですね^^
![]()
![]()
この記事を書いたひと:福田 聡樹(ふくだ さとき)
株式会社プロトソリューション Webマーケティング部所属。自社ホームページ編集長。ブログ/インタビュー/動画などのコンテンツを使って、プロトソリューションのサービスやタレント情報を発信しています。
好きなもの:爬虫類全般、本のにおい。







